How we checked our accuracy against Lichess
Every chess app shows an "accuracy" number after a game. We wanted to know whether ours actually tracks how well you played, so we tested it against a public reference.
We took 800 grandmaster player-games, scored them with the same code that ships in the app, and compared every score against Lichess's own. Here's what came out.
The short version
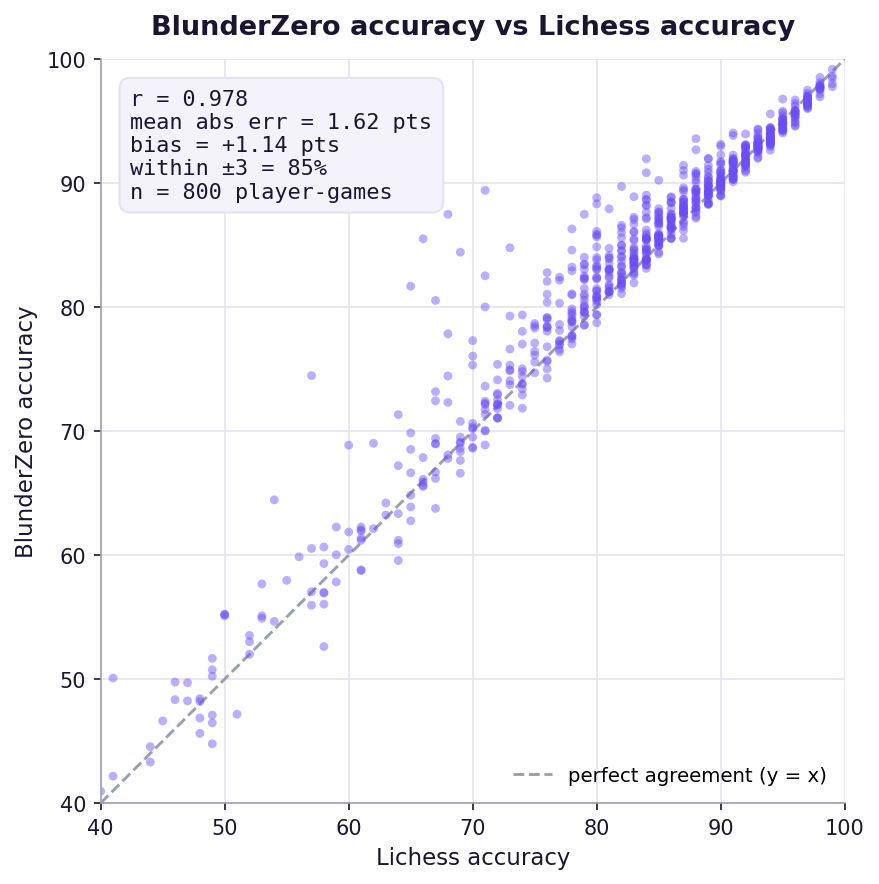
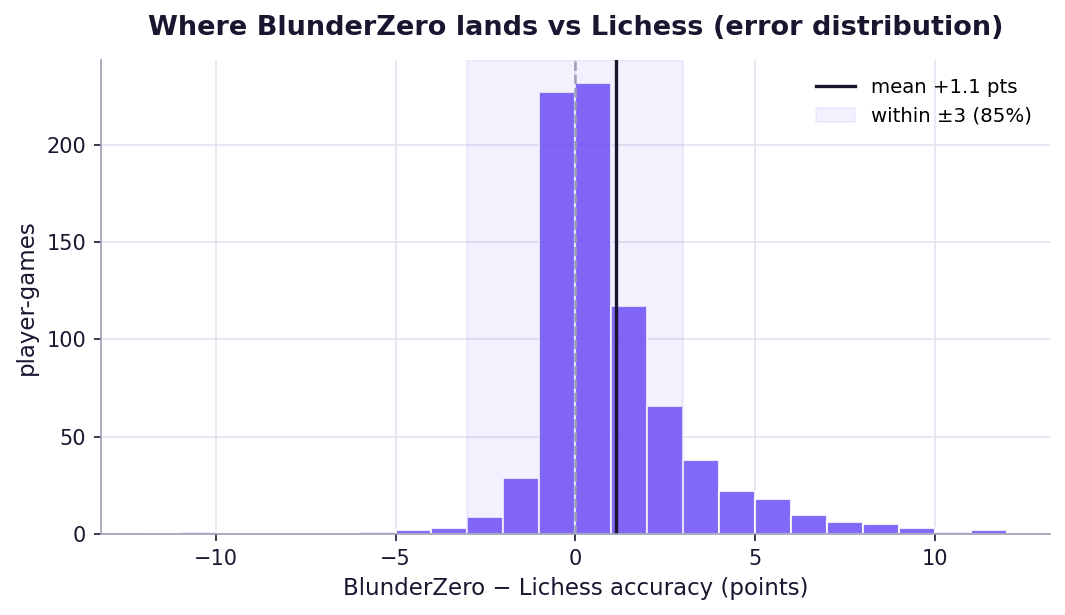
Across 800 player-games (both sides of ~400 grandmaster games), BlunderZero's accuracy matches Lichess's own accuracy with a Pearson correlation of r = 0.978, a mean error of about 1.6 points out of 100, and 85% of player-games within ±3 points.
A mean absolute error of ~1.6 points means that, on a typical game, the accuracy BlunderZero shows you and the one Lichess would show you differ by little more than a single point, and they agree within ±3 points on 85% of games.
How accuracy actually works
We use the same eval-loss method Lichess uses, and the per-move accuracy curve Chess.com publishes, in three steps:
- Eval → winning chance. A position's engine evaluation (say, +1.5 pawns) is converted to a winning probability with a standard logistic curve. Being up a pawn early matters less than being up a pawn in a sharp endgame; win% captures that.
- Per-move accuracy comes from how much winning chance you gave up on that move. Give up nothing → 100. Hang your queen → close to 0.
- Game accuracy combines your per-move scores. A plain average would let one blunder hide behind twenty good moves, so we use a harmonic, volatility-weighted blend (the same reason your Chess.com or Lichess accuracy drops sharply after a single disaster).
The combine is where homegrown accuracy scores usually go off, and it's what we fixed on the way to r = 0.978. An earlier build used a plain average and read about 7 points high; the per-move curve was already fine, the combine was doing the damage.
Why Lichess is our reference
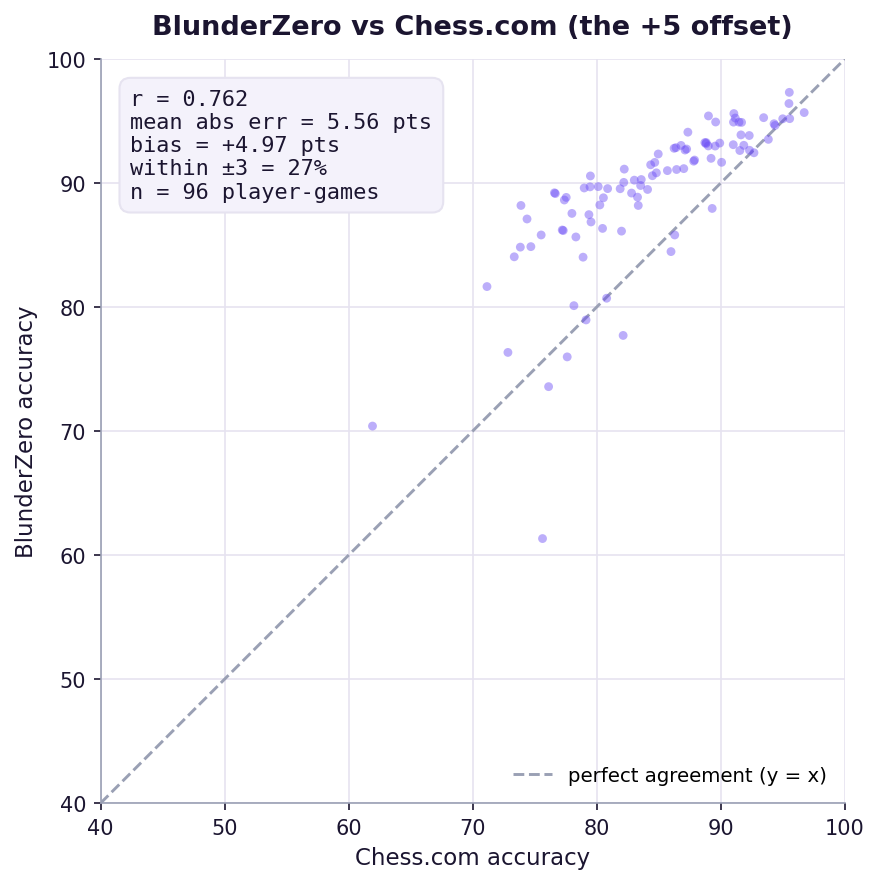
We also ran the test against Chess.com, where we read about 5 points higher than their number (r ≈ 0.76). Here's why, since it's worth explaining.
Depth isn't the cause. Analyzing the same games 50% deeper moved the gap by less than a point, and our score barely changes with depth. The difference is the model: Chess.com publishes its per-move curve, which we use, but its game-level accuracy model is proprietary and runs harsher than any eval-based combine, Lichess included. We calibrated to the reference you can actually pull and reproduce. Chasing Chess.com's game number would mean reverse-engineering a model no one can see, and we'd land five points off from Lichess instead.
So we picked the reference you can actually verify yourself.
Where the numbers come from
The corpus is public. Every game, its per-move evals, and Lichess's own accuracy come straight from the public Lichess API, so you can pull the exact same games we tested:
# 8 GMs x 50 = ~400 games (800 player-games):
for u in DrNykterstein Zhigalko_Sergei penguingm1 EricRosen nihalsarin \
Vladimirovich9000 alireza2003 Konevlad; do
curl -s -H "Accept: application/x-ndjson" \
"https://lichess.org/api/games/user/$u?max=50&evals=true&accuracy=true&analysed=true"
echo
done > /tmp/lichess_corpus.ndjson
We score those same games with the accuracy code that ships in the app and compare each one against Lichess's number. We re-run this on every release, and the result is what you see above: r = 0.978 across 800 player-games. The games and the reference are public, so the inputs are never ours to massage.